YOLO 학습을 할 때, YOLO mark-master 라는 프로그램을 이용해서 학습시킬 데이터를 만들 수 있다.
이미지에 일일이 손으로 네모모양 box로 영역을 설정하여 해당 부분이 학습될 수 있도록 해야한다.
YOLO에서 학습을 하는데 사용한 coco dataset의 markup영역을 확인하면, 의외로 꼼꼼히 marking 했고, 상당 수의 makring을 했다는 것을 알 수 있다.
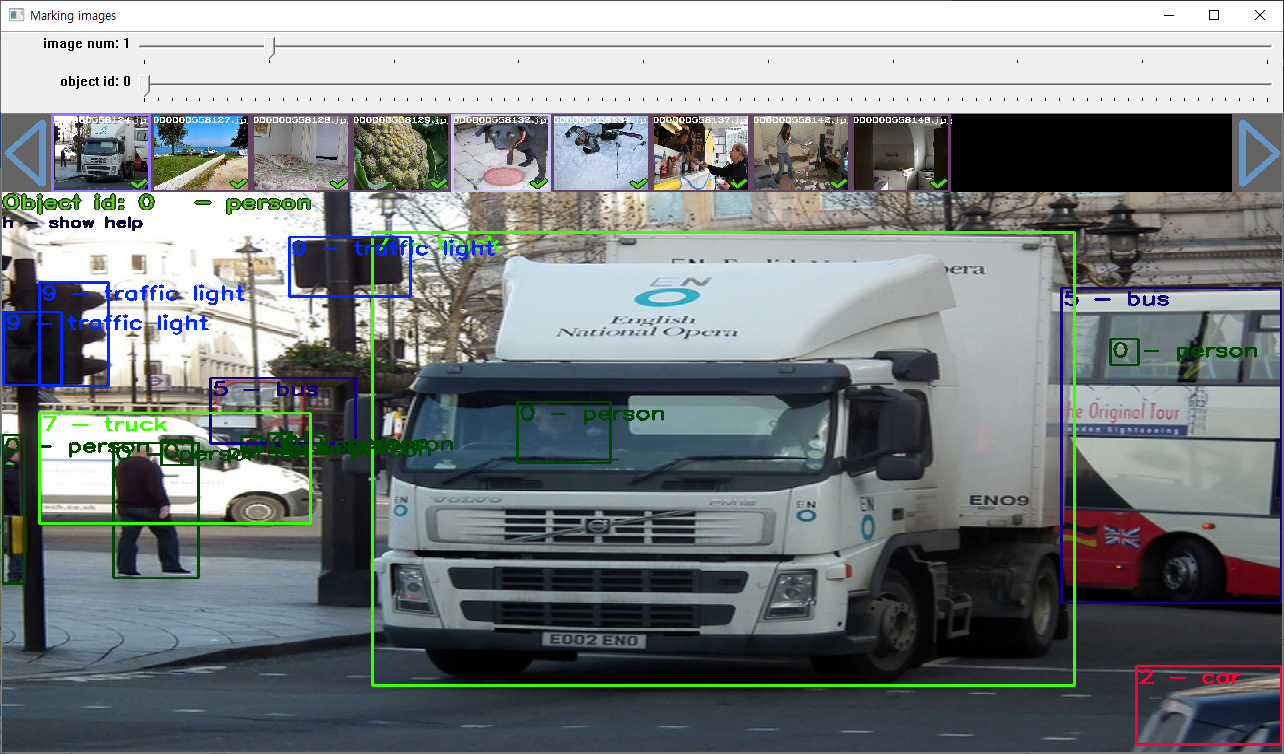
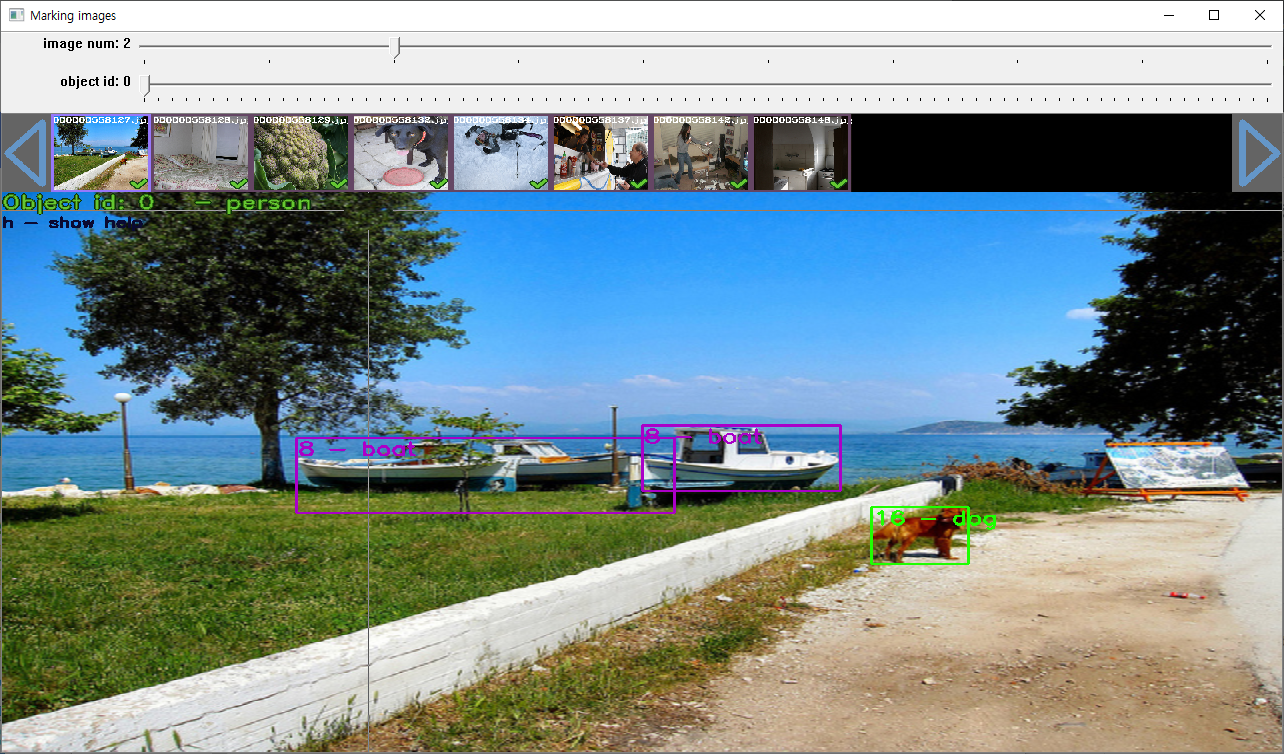
기본 제공되는 mark를 보고 YOLO에서는 어떤 기준을 가지고 mark를 했는지 나름대로 분석해봤다.
*마킹 분석( 기본 이미지 마킹 방식 )
1. 학습시키고자 하는 물체의 끝선에 맞춰서 영역을 지정함.
2. 물체가 작던지, 크던지, 사람이 인지 할 수 있는 수준의 물체이고, 학습 시켜야 할 물체라면 반드시 마킹한다.
3. 학습하고자 하는 물체가 겹칠 경우 신경쓰지 않고, 가장 뒷쪽에 있는 물체부터 그 물체의 일부가 조금이라도 보이는 위치까지 마킹한다.
#자체적인 경험
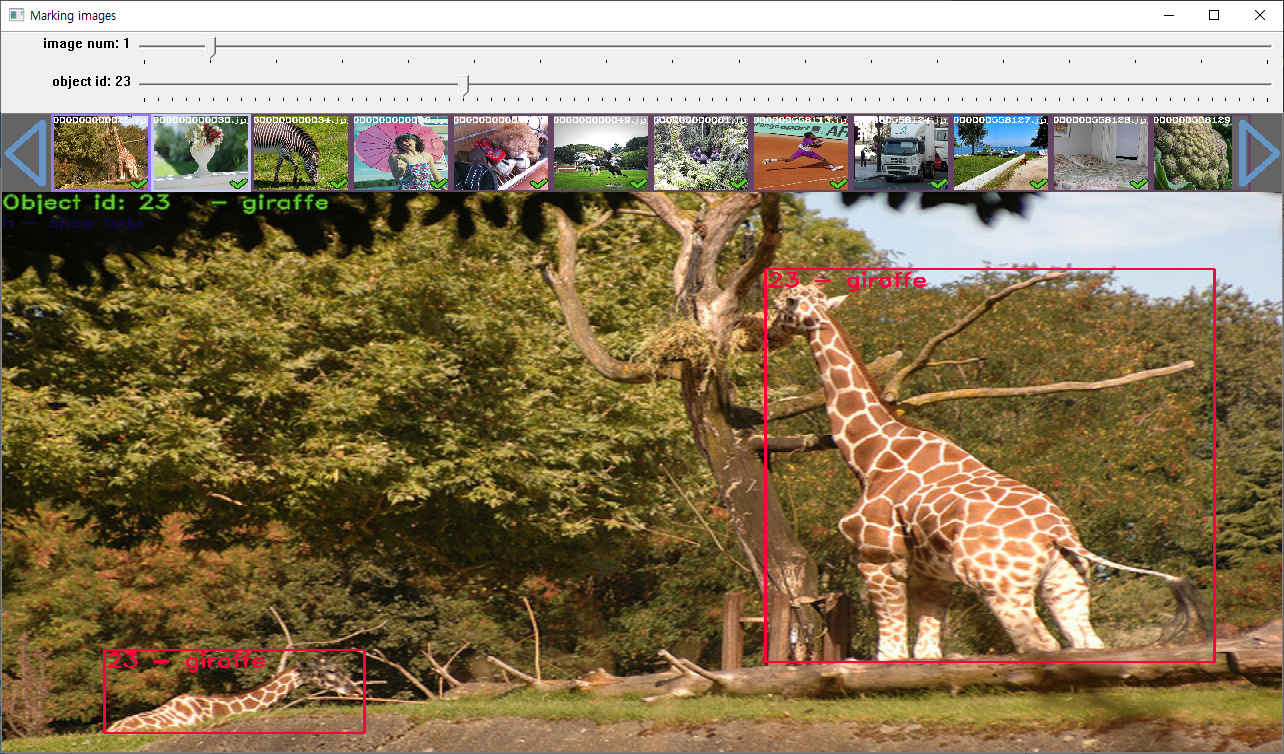
꼭 물체의 끝점에 맞춰 객체를 학습 시킬 필요는 없어보인다. 객체의 특징을 읽어내는데에는 문제가 없어보인다.
가지고있는 사진 12000장을 일일이 손으로 마킹해가며 학습을 시켜본 결과 객체를 찾는데에는 문제가 없었다.
다만 심층적으로 분석을 한 것이 아니기 때문에 학습을 방해하는 요소로 포함되는지, 혹은 정확도를 올리는데 문제가 있는지는 모르겠다.
다만 12000장에 대하여 기본 이미지 마킹처럼 꼼꼼히 마킹도 해보고, 큼직큼직 하게 마킹도 해보았지만, 당장 결과를 보는데에는 큰 문제가 없었다.

'AI' 카테고리의 다른 글
| darknet yolo 실행을 위해 필요한 프로그램 (0) | 2020.05.01 |
|---|---|
| YOLO 학습에 대한 잡다한 지식(기본, 배경 지식) (2) | 2020.03.05 |
| YOLO 동작 시 화면에 있는 퍼센트(확률) 지우기 (3) | 2020.03.05 |
| YOLO 학습 환경(PC 스펙) (4) | 2020.03.04 |
| Darknet YOLO에서 사용하는 학습(train) 이미지 구하기(YOLO 기본 이미지 변환) (3) | 2020.03.03 |



